Featured Projects
Bank Customer Churn Prediction & Explainability
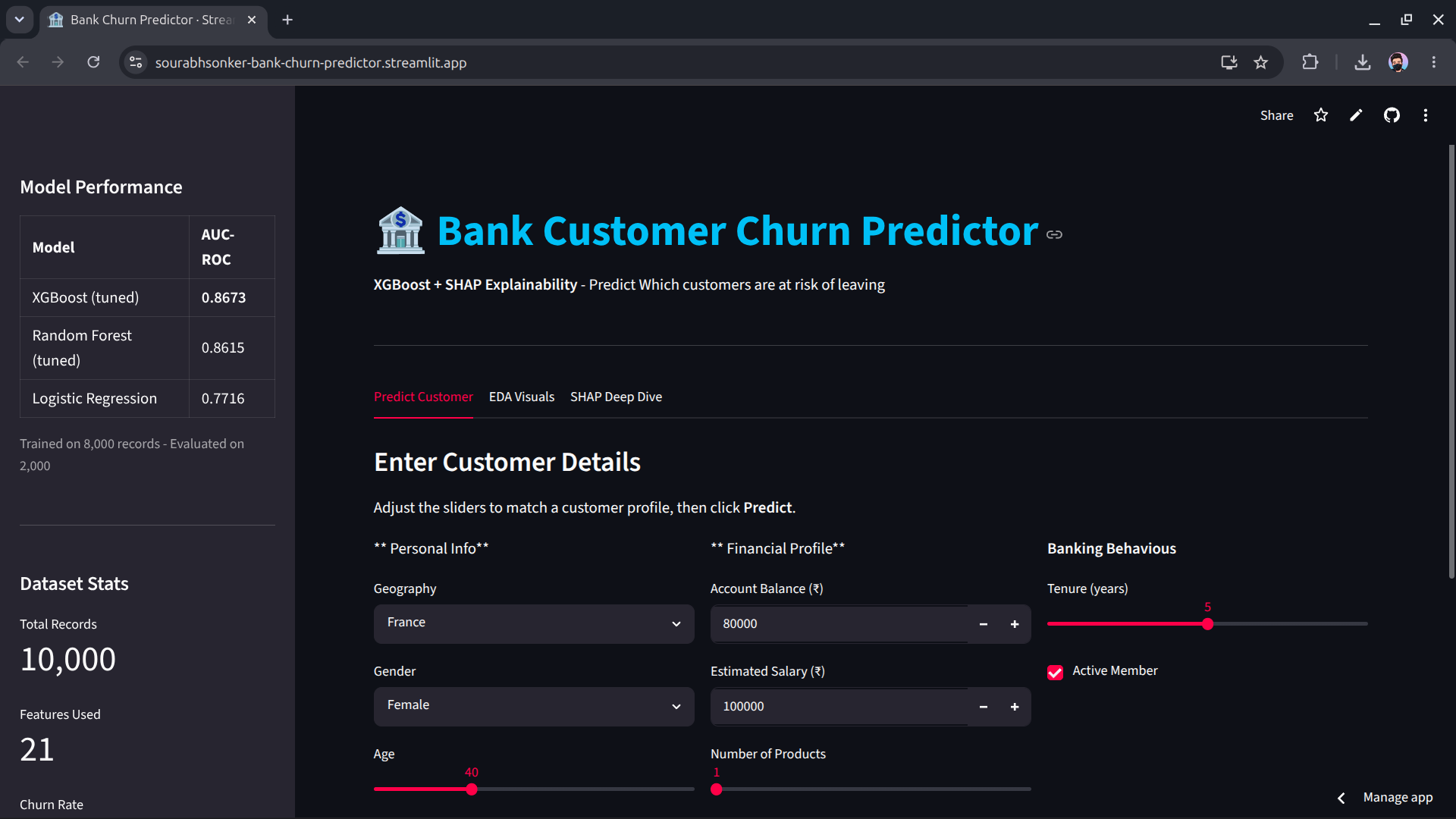
Full ML lifecycle on 10,000 bank customer records — imbalanced data handling, Bayesian hyperparameter tuning, and SHAP-powered per-customer explainability. Business framing throughout: quantifying the real cost of missing a churn event.
- Benchmarked 3 models: XGBoost (86.9%) · RF (86.2%) · LR (77.2%) with stratified evaluation; Optuna Bayesian tuning (50 trials) added +3.6 pts over untuned baseline
- Engineered 4 domain features — products_per_tenure ranked #2 in SHAP importance, capturing the non-linear 3–4 product churn cliff
- SHAP TreeExplainer identified top 5 levers: age 41–60, Germany geography, inactive membership, mono-product high-balance holders, credit score <600
Financial News Sentiment Analysis + Stock Correlation
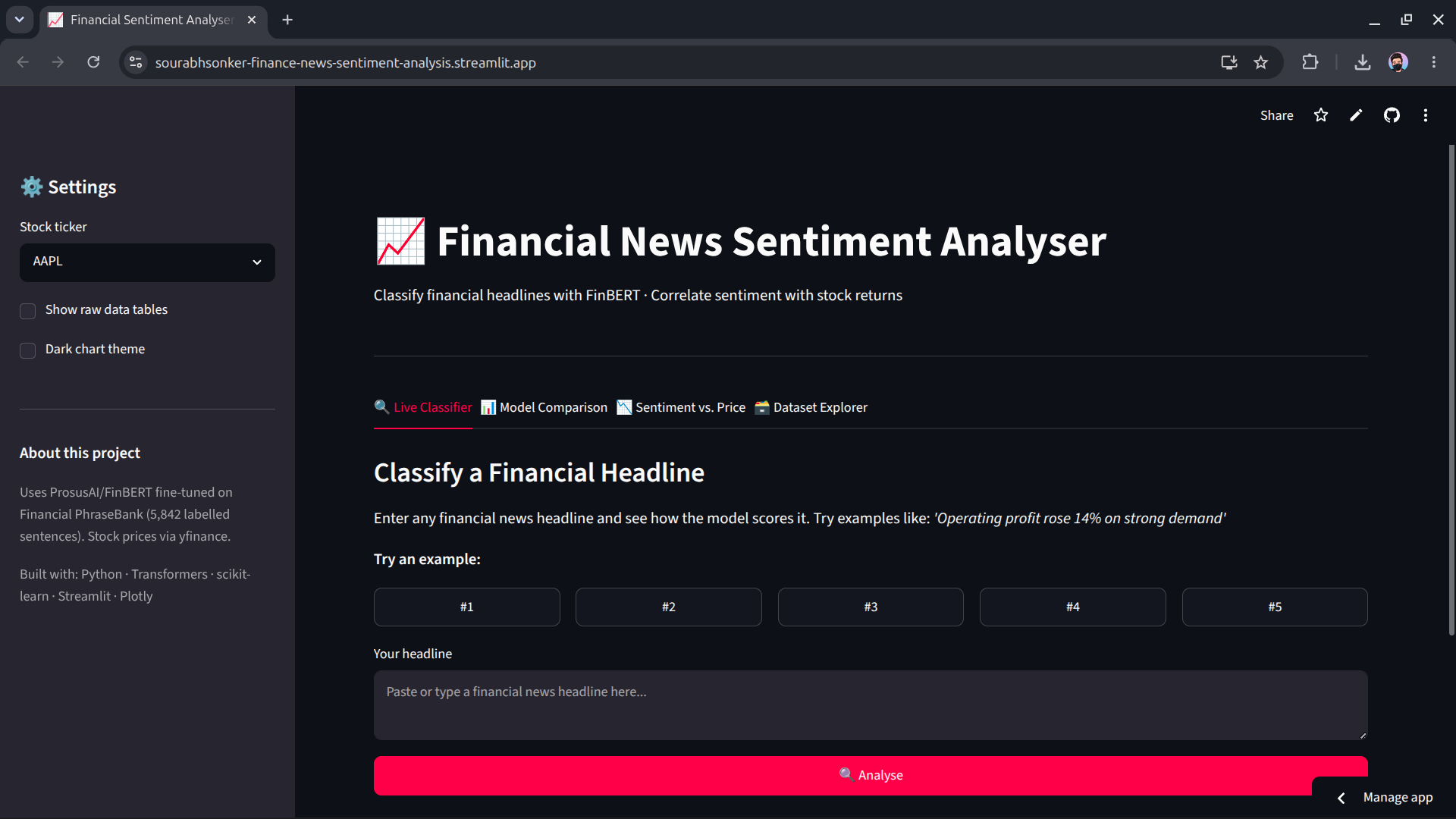
Finance-domain NLP using FinBERT — a BERT model pre-trained on financial text. Goes beyond accuracy: ablation studies, a caught evaluation bug, and a statistically honest sentiment-price correlation study across 5 tickers and 2 years of data.
- FinBERT zero-shot: 4.3× improvement in bearish detection (F1: 0.14 → 0.60) over TF-IDF+SVM; domain-aware preprocessing validated via ablation study
- Identified and corrected a label-misalignment bug that inflated VADER baseline by 25.3 percentage points — caught through EDA notebook review
- 4-tab Streamlit dashboard; ~1hr cold-start resolved by precomputing FinBERT artifacts; yfinance rate-limiting fixed via precomputed CSVs
Retail + NSE Stock Time Series Forecasting
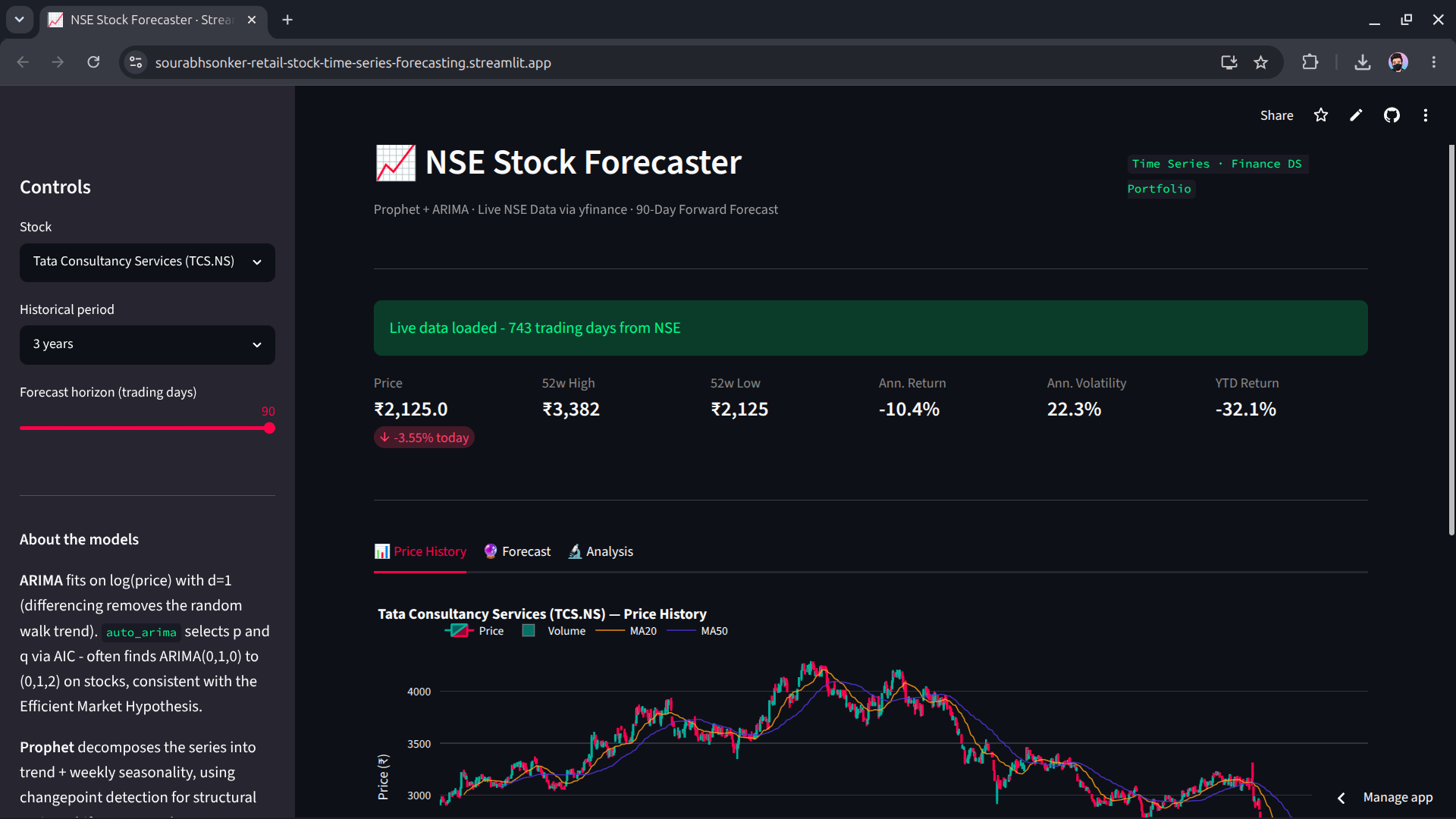
Dual-domain forecasting — 3M+ rows of retail data plus live NSE stock prices. Every modelling decision is documented and justified: why SARIMA beat Prophet here, what the earthquake spike means, why stock MAPE is higher than retail MAPE.
- SARIMA: 8.8% MAPE on 90-day retail horizon; Prophet 12.1% — advantage absent in holiday-free Jun–Aug 2017 test window (documented with reasoning)
- Macro signal: WTI oil price r = −0.47 with Ecuador grocery sales; April 2016 earthquake modelled as named Prophet event (2× normal Saturday demand)
- Extended to live NSE stocks; ARIMA(0,1,1) order consistent with weak-form EMH — documented as insight, not buried; Streamlit app supporting 10 tickers
House Price Prediction — End-to-End MLOps Pipeline
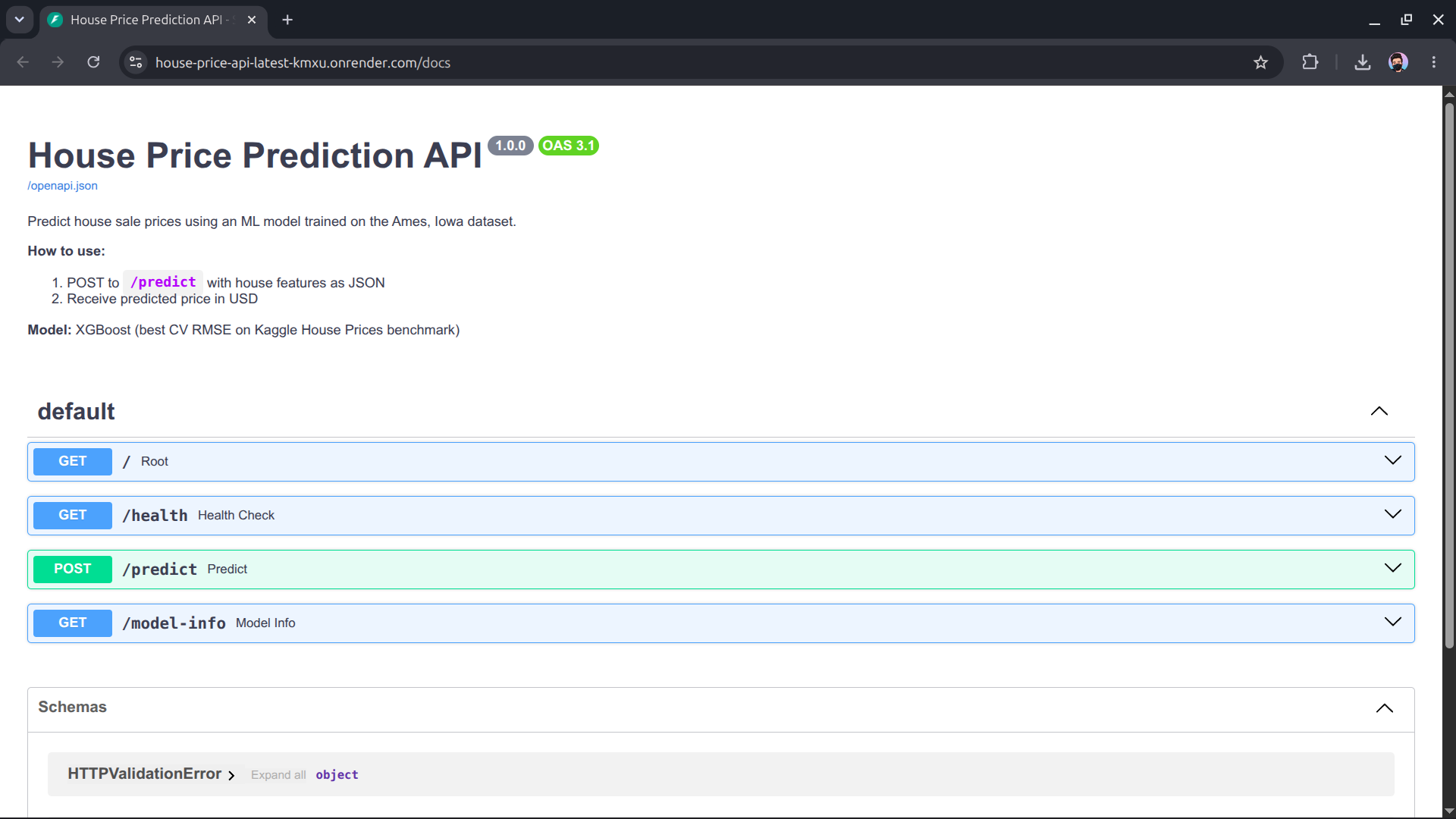
Production ML engineering from pipeline design to live deployment. A leak-proof sklearn pipeline, MLflow experiment tracking, FastAPI REST service, Docker container, and GitHub Actions CI/CD that auto-deploys on every push — with failing tests blocking deployment.
- ColumnTransformer fit exclusively on training folds — prevents data leakage; MLflow tracking: XGBoost selected at CV RMSLE 0.1209 over LightGBM (0.1284), Ridge (0.1392)
- FastAPI with Pydantic validation and Swagger UI; multi-stage Docker build; GitHub Actions CI/CD — tests → retrain → build → deploy; failing tests block deployment
- Diagnosed and resolved 5 independent production issues including CI mock scoping and Docker image bloat
RAG-Based Document Q&A System
End-to-end Retrieval-Augmented Generation pipeline. Upload any PDF or text document, ask questions in natural language, get answers grounded strictly in the source content — with multi-turn conversation memory and zero hallucination by design.
- PyPDF2 → RecursiveCharacterTextSplitter (800-char/100-overlap) → all-MiniLM-L6-v2 embeddings → FAISS vector store for semantic retrieval
- Dual LLM backends: Google Gemini 2.5 Flash + Groq Llama 3 via LangChain; custom anti-hallucination system prompt constrains answers to retrieved context only
- ConversationBufferMemory for multi-turn Q&A; @st.cache_resource model caching eliminates per-request reload; deployed on Streamlit Cloud